TL;DR
This blogpost shows an example for a Chatbot that uses Retrieval Augmented Generation to retrieve domain specific knowledge before querying a Large Language Model
Hands on with Retrieval Augmented Generation
For a primer on Retrieval Augmented Generation please read my other post What is Retrieval Augmented Generation?.
Retrieval Augmented Generation can be a powerful architecture to easily built knowledge retrieval applications which (based on a recent study) even outperform LLM’s with long context windows.
Prerequisites
All the code mentioned here can be found on github. The code can be run in a Docker container(even on a Raspberry Pi if you like). You need to add contextual data which you want to query and also use an API Key from OpenAI.
Dependencies
The complete python code is containerized with docker and can be run via docker compose. It uses the following main dependencies:
- streamlit as an easy to use an easy to implement Frontend. No need to set up Flask and debug through your CSS. Streamlit is open-source.
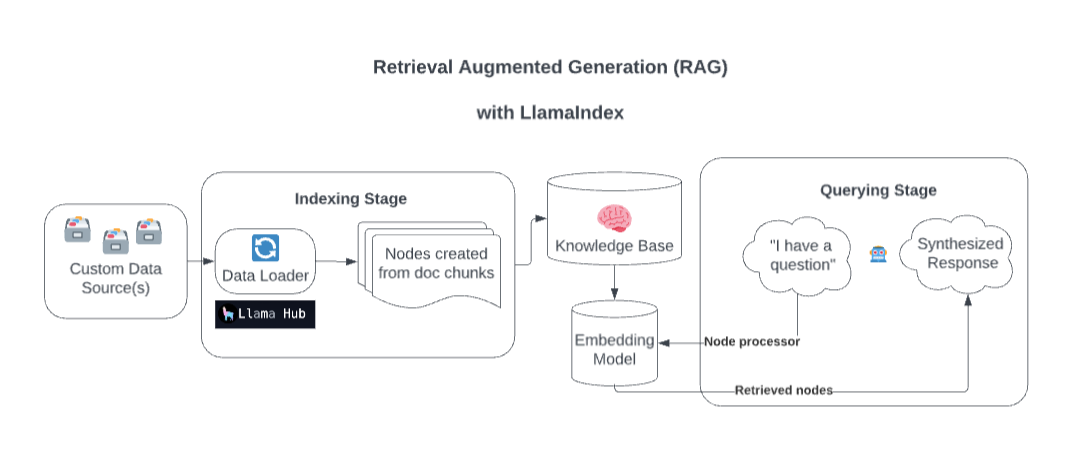
- llama_index which is used to build the retrieval engine. It is a simple, flexible data framework for connecting custom data sources to large language models. It is somehow similar to LangChain
- openai provides access to the OpenAI API
Other packages are used to convert the context data. All dependencies can be found in the requirements.txt
Overview
The Knowledge Bot is a web-based chatbot that provides information and answers questions related to any data which is given as context based on Retrieval Augmented Generation Architecture. It utilizes the llama_index library for data indexing and OpenAI’s GPT-3.5-Turbo model for generating responses.
The chatbot is designed to assist users in finding information by answering questions based on indexed documents.
 picture from streamlit
picture from streamlit
Features
- Ask questions related to your indexed documents.
- Receive informative responses based on indexed data.
- Convenient web-based interface powered by Streamlit.
Setup
To run the Knowledge Bot locally with docker, follow these steps:
-
Clone this repository to your local machine:
git clone https://github.com/PatrickPT/RAG_LLM_example.git -
Create your OpenAI Key
cd RAG_LLM_example cd .streamlit nano .streamlit/secrets.toml # Insert your API Key as openai_key = "API Key" and save -
Create your documents or change the input_dir parameter in config.yaml to your folder(which needs to be accessible from the docker container)
cd data # Insert the contextual documents the LLM should use in that folder -
Change the
config.yamlfile accordingly to your prior changes-config: api: gpt-3.5-turbo info: This bot knows everything about PromptEngineering which is mentioned in the guides in https://www.promptingguide.ai/ input_dir: ./data name: Knowledge Bot system_prompt: You are an expert on Prompt Engineering and Retrieval Augmented Generation with Large Language Models. Assume that all questions are related to Prompt Engineering. Keep your answers technical and based on facts. Do not hallucinate features. -
Run docker compose
docker compose up -d
PS: content in /.streamlit and /data is ignored by git.
Code
This small project is a Streamlit-based web application that serves as a chatbot powered by the “llama_index” package and OpenAI’s GPT-3.5-Turbo model. It allows users to ask questions related to all documents which are stored in /data and provides informative responses.
Several libraries, including streamlit, llama_index, openai, and others are imported.
import streamlit as st
from llama_index import VectorStoreIndex, ServiceContext, Document
from llama_index.llms import OpenAI
import openai
from llama_index import SimpleDirectoryReader
import yaml
The configuration is imported from config.yaml
with open("config.yaml", "r") as yamlfile:
config = yaml.load(yamlfile, Loader=yaml.FullLoader)
# import configuration from yaml
name = config[0]['config']['name']
info = config[0]['config']['info']
input_dir = config[0]['config']['input_dir']
system_prompt = config[0]['config']['system_prompt']
api = config[0]['config']['api']
The Streamlit app’s title, icon, layout, and sidebar state are configured.
# Set Streamlit page configuration
st.set_page_config(
page_title=name,
page_icon="🦙",
layout="centered",
initial_sidebar_state="auto",
menu_items=None
)
OpenAI API key is set using a secret obtained from Streamlit secrets. The key is stored in /.streamlit/secrets.toml
# Set OpenAI API key
openai.api_key = st.secrets.openai_key
Create the main interface: title and information message about the bot’s capabilities is configured.
# Create main interface
st.title(name)
st.info(info, icon="📃")
A list called messages is initialized in Streamlit session state, which will be used to store the chat history.
# Initialize the chat messages history
if "messages" not in st.session_state.keys():
st.session_state.messages = [
{"role": "assistant", "content": "Ask me a question"}
]
A function called load_data is built, that loads and indexes data from /data. This data is used for responding to user queries.
# Function to load data
@st.cache_resource(show_spinner=False) # data is cached in memory so limit the knowledge base according to your machine
def load_data():
with st.spinner(text="Loading and indexing the provided data"):
reader = SimpleDirectoryReader(input_dir=input_dir, recursive=True) # read recursively all directories
docs = reader.load_data() # load data and create docs
service_context = ServiceContext.from_defaults(llm=OpenAI(model=api, temperature=0.5, system_prompt=system_prompt)) # add a permanent service prompt which is added
index = VectorStoreIndex.from_documents(docs, service_context=service_context) # create your vector database
return index
Call the load_data function to load and index the data. Also a chat engine is initialized using the indexed data.
# Load data and create the chat engine
index = load_data()
chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
Check if the user has entered a question through the Streamlit chat input widget. If there is user input, it is appended to the chat history.
# User input and chat history
if prompt := st.chat_input("Your question"):
st.session_state.messages.append({"role": "user", "content": prompt})
Loop through the chat history and displays all previous messages in the chat interface.
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
Checks if the last message in the chat history is not from the assistant (bot). If it’s not from the assistant, a response is generated using the chat engine and added to the chat history.
# Generate a response if the last message is not from the assistant
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = chat_engine.chat(prompt)
st.write(response.response)
message = {"role": "assistant", "content": response.response}
st.session_state.messages.append(message)
Resources
Build a chatbot with custom data sources, powered by LlamaIndex