TL;DR
Parameter Efficient Fine-Tuning is a technique that aims to reduce computational and storage resources during the fine-tuning of Large Language Models.
Why should i care?
Fine-tuning is a common technique used to enhance the performance of large language models. Essentially, fine-tuning involves training a pre-trained model on a new, similar task. It has become a crucial step in model optimization. However, when these models consist of billions of parameters, fine-tuning becomes computational and storage heavy, leading to the development of Parameter Efficient Fine-Tuning methods.
Parameter Efficient Fine-Tuning is a collection of techniques that aim to reduce computational and storage resources during the fine-tuning process. Rather than tuning all parameters, these methods strategically select and fine-tune a fraction of them. The rest of the parameters are frozen or updated with a lower precision format, saving memory and computational requirements. This technique also mitigates the risk of overfitting, enhances learning efficiency, and allows for more adaptability in applying large language models across a variety of tasks.
Use Parameter-Efficient Fine-Tuning
The process of parameter-efficient fine-tuning (PEFT) may exhibit variations depending on the specific implementation and the pre-trained model in use. Nevertheless, below are summarized all steps involved in PEFT:
Pre-training: Initially, a large-scale model undergoes pre-training on a substantial dataset, commonly for a generic task like image classification or language modeling. This phase equips the model with foundational knowledge and meaningful data representations. Task-specific dataset: Assemble or generate a dataset tailored to the particular task for which you intend to fine-tune the pre-trained model. This dataset must be labeled and faithfully represent the target task.
Parameter identification: Identify or estimate the significance and relevance of parameters within the pre-trained model for the target task. This step helps in discerning which parameters should be prioritized during the fine-tuning process. Techniques such as importance estimation, sensitivity analysis, or gradient-based methods can be employed for parameter assessment.
Subset selection: Choose a subset of the pre-trained model’s parameters based on their importance or applicability to the target task. The selection process can involve setting specific criteria, like a threshold on importance scores or selecting the top-k most relevant parameters.
Fine-tuning: Initialize the chosen subset of parameters with values from the pre-trained model and lock the remaining parameters. Fine-tune the selected parameters by employing the task-specific dataset. This typically entails training the model on the target task data using optimization techniques like Stochastic Gradient Descent (SGD) or Adam.
Evaluation: Assess the performance of the fine-tuned model on a validation set or by utilizing relevant evaluation metrics for the target task. This step serves to gauge the efficacy of PEFT in achieving the desired performance while reducing the number of parameters.
Iterative refinement (optional): Depending on performance and specific requirements, you may opt to iterate and refine the PEFT process. This can involve adjusting the criteria for parameter selection, exploring different subsets, or conducting additional fine-tuning epochs to further optimize the model’s performance. It’s crucial to note that the specific implementation details and techniques employed in PEFT can differ across research papers and real-world applications.
PEFT Techniques
Adapter Modules
Adapter modules represent a specialized type of component that can be integrated into pre-trained language models to tailor their hidden representations during the fine-tuning process. These adapters are typically inserted following the multi-head attention and feed-forward layers within the transformer architecture, allowing for selective updates to the adapter parameters while keeping the remainder of the model parameters unchanged.
Incorporating adapters is a straightforward procedure. The essential steps involve adding adapter modules to each transformer layer and positioning a classifier layer atop the pre-trained model. By updating the parameters of the adapters and the classifier head, one can enhance the pre-trained model’s performance on specific tasks without the need for a comprehensive model update. This approach not only saves time but also conserves computational resources while delivering notable results.
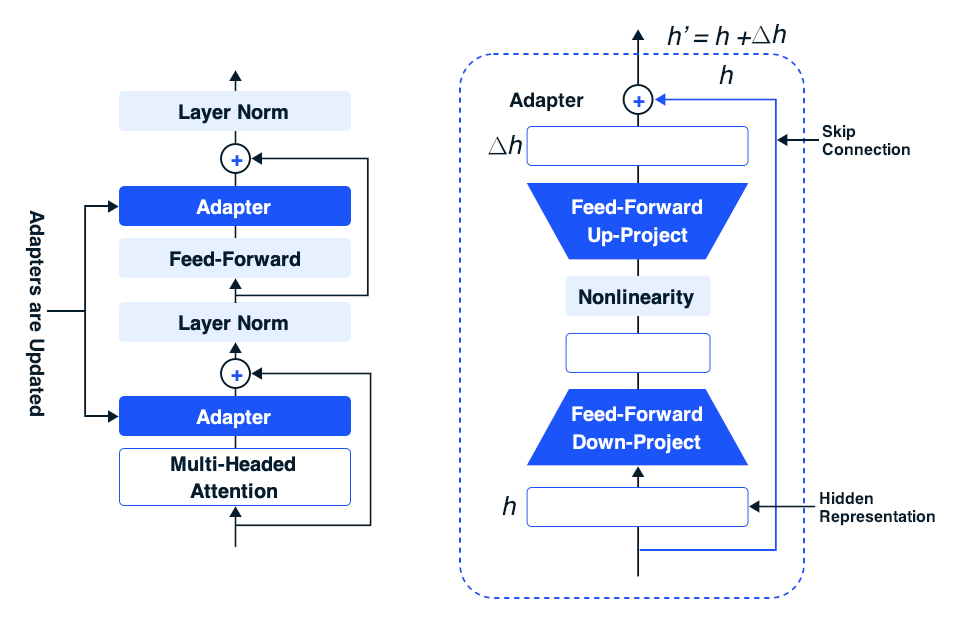
But how does fine-tuning using an adapter actually work? The adapter module itself consists of two feed-forward projection layers linked by a non-linear activation layer, and it incorporates a skip connection that bypasses the feed-forward layers.
Consider an adapter placed immediately after the multi-head attention layer. In this case, the input to the adapter layer is the hidden representation denoted as h' derived from the multi-head attention layer. Within the adapter layer, h follows two distinct paths: one through the skip connection, which leaves the input unaltered, and the other through the feed-forward layers, facilitating the necessary modifications.
 picture from A Guide to PEFT
picture from A Guide to PEFT
To begin, the first feed-forward layer initially projects h into a lower-dimensional space, which has fewer dimensions than h itself. Subsequently, the input traverses through a non-linear activation function, and the second feed-forward layer then reprojects it back to the same dimensionality as h. The outcomes generated by these two paths are combined through summation to yield the adapter module’s ultimate output.
The skip-connection dutifully maintains the original input h of the adapter, while the feed-forward path generates an incremental alteration, denoted as Δh, predicated on the original h. By introducing this incremental change, Δh, acquired from the feed-forward layer, to the original h from the previous layer, the adapter orchestrates a modification to the hidden representation calculated by the pre-trained model. This process empowers the adapter to adapt the pre-trained model’s hidden representation, thereby influencing its output for a specific task.
LoRA
Low-Rank Adaptation (LoRA) in the context of fine-tuning large language models offers an alternative approach for tailoring models to specific tasks or domains. Much like adapters, LoRA is a compact trainable submodule that seamlessly integrates into the transformer architecture. LoRA operation involves preserving the pre-trained model weights while introducing trainable rank decomposition matrices into each layer of the transformer architecture. This process significantly reduces the number of trainable parameters for downstream tasks. Remarkably, LoRA can achieve a reduction of up to 10,000 times in the number of trainable parameters and reduce GPU memory requirements by a factor of 3, all while maintaining or surpassing the performance of fine-tuned models across various tasks. LoRA also facilitates more efficient task-switching, lowers hardware constraints, and incurs no additional inference latency.
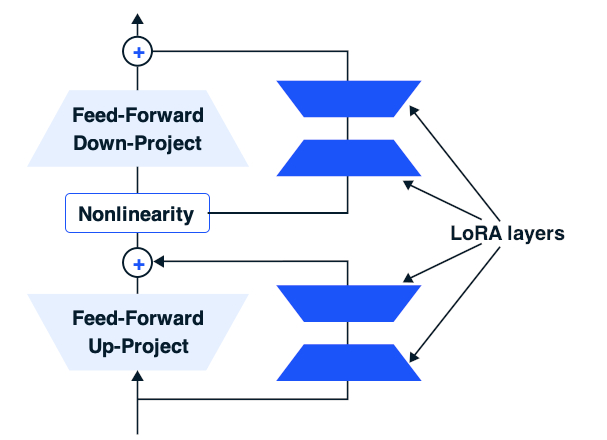
So, how does LoRA function? LoRA modules are inserted in parallel with the components of the pre-trained transformer model, specifically adjacent to the feed-forward layers. Each feed-forward layer includes two projection layers separated by a non-linear layer, wherein an input vector is transformed into an output vector with different dimensionality using an affine transformation. The LoRA layers are positioned alongside each of the two feed-forward layers.
 picture from A Guide to PEFT
picture from A Guide to PEFT
Now, let’s delve into the interaction between the feed-forward up-project layer and the adjacent LoRA module. The original parameters of the feed-forward layer take the output from the preceding layer, which is represented by dmodel, and project it into dFFW (where FFW stands for feed-forward). The adjacent LoRA module comprises two feed-forward layers. The first of these takes the same input as the feed-forward up-project layer and projects it into an r-dimensional vector, significantly smaller than dmodel. Subsequently, the second feed-forward layer transforms this vector into another vector with a dimensionality of dFFW. The two vectors are then combined through addition to create the final representation.
As discussed earlier, fine-tuning involves adjusting the hidden representation h computed by the original transformer model. In this context, the hidden representation generated by the feed-forward up-project layer of the original transformer corresponds to h. Simultaneously, the vector computed by the LoRA module represents the incremental change Δh applied to modify the original h. Consequently, the summation of the original representation and the incremental change yields the updated hidden representation h.
By incorporating LoRA modules alongside the feed-forward layers and a classifier head atop the pre-trained model, task-specific parameters for each individual task are kept to a minimum.
QLoRA
Compressing model parameters even more, QLoRA – or Quantized LoRA – takes the concepts of LoRA and applies a quantization technique. Instead of storing these new low-rank parameters in standard floating-point format, QLoRA stores them in a lower precision format, such as INT8 or INT4.
This method drastically reduces the number of bits required to store these parameters. As a result, QLoRA offers a significant reduction in the memory and computational requirements, vastly improving parameter efficiency during the fine-tuning process.
Prefix Tuning
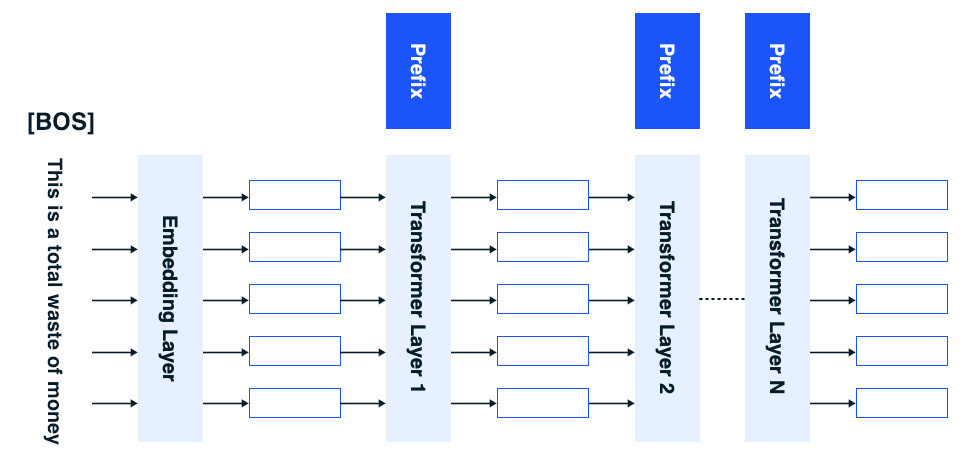
Prefix-tuning offers a lightweight and cost-effective alternative to the conventional fine-tuning of large pre-trained language models for natural language generation tasks. Traditional fine-tuning entails the comprehensive updating and storage of all model parameters for each specific task, an endeavor that can be financially burdensome given the expansive scale of contemporary models. In contrast, prefix-tuning maintains the pre-trained language model parameters unchanged and focuses on optimizing a small, continuous, task-specific vector known as the “prefix.” In prefix-tuning, the prefix constitutes a set of independent parameters that undergo training alongside the language model. The primary aim of prefix-tuning is to discover a context that guides the language model to generate text that effectively addresses a particular task.
The prefix can be perceived as a sequence of “virtual tokens” to which subsequent tokens can attend. Remarkably, by updating a mere 0.1% of the model’s parameters, prefix-tuning manages to achieve performance comparable to traditional fine-tuning in full-data settings, outperforming it in scenarios with limited data, and exhibiting superior extrapolation to examples featuring topics not encountered during training.
 picture from A Guide to PEFT
picture from A Guide to PEFT
Much like the aforementioned PEFT techniques, the ultimate objective of prefix-tuning is to attain h prime (h'). Prefix-tuning utilizes these prefixes to adapt the hidden representations derived from the original pre-trained language models. The modification is achieved by adding the incremental change Δh to the initial hidden representation h' resulting in the modified representation h prime (h').
In the realm of prefix-tuning, only the prefixes undergo updates, while the remainder of the model’s layers remain static and unchanged. This focused approach allows for enhanced efficiency and economy in addressing natural language generation tasks.
Prompt Tuning
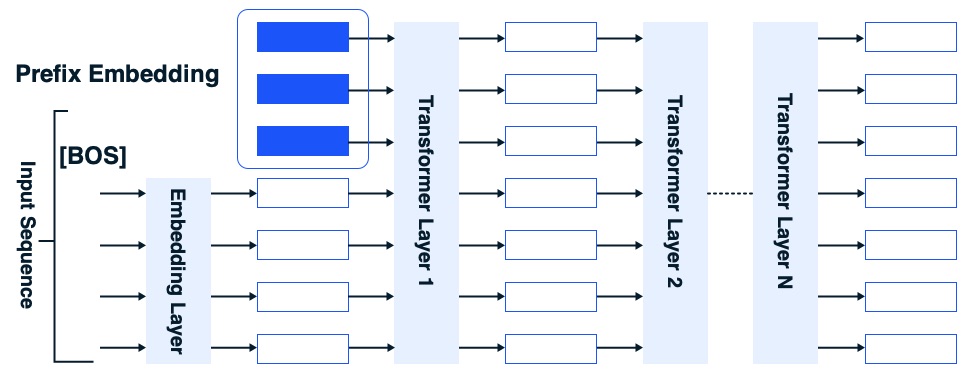
Prompt tuning stands as a potent PEFT technique designed for the precise adaptation of pre-trained language models to specific downstream tasks. Unlike the conventional “model tuning” approach, where every parameter in the pre-trained model undergoes adjustments for each task, prompt tuning introduces the concept of learning soft prompts through backpropagation. These soft prompts can be fine-tuned for distinct tasks by incorporating labeled examples. The results are remarkable, as prompt tuning excels in outperforming few-shot learning methods like GPT-3, particularly gaining competitiveness as model sizes expand. It bolsters the robustness of domain transfer and opens the door to efficient prompt ensembling. Unlike model tuning, which necessitates creating task-specific copies of the entire pre-trained model for each task, prompt tuning simply requires storing a small task-specific prompt for each task. This approach simplifies the process of reusing a single frozen model across a multitude of downstream tasks.
 picture from A Guide to PEFT
picture from A Guide to PEFT
Prompt tuning serves as a simplified variant of prefix tuning. In this method, specific vectors are appended at the commencement of a sequence, specifically at the input layer. When presented with an input sentence, the embedding layer proceeds to convert each token into its corresponding word embedding, while the prefix embeddings are prepended to the sequence of token embeddings. Subsequently, the pre-trained transformer layers process the entire embedding sequence in a manner akin to how a transformer model treats a standard sequence. During the fine-tuning process, only the prefix embeddings undergo adjustments, while the remainder of the transformer model remains locked and unaltered.
Prompt tuning offers numerous advantages compared to traditional fine-tuning approaches. It significantly enhances efficiency and mitigates computational demands. Furthermore, the exclusive fine-tuning of prefix embeddings minimizes the risk of overfitting to the training data, thereby producing models that are more resilient and capable of generalizing effectively.
Benefits
Cost Savings: PEFT significantly reduces computational and storage costs by fine-tuning a small number of additional model parameters while keeping most of the pre-trained LLM parameters frozen.
Mitigating Knowledge Loss: PEFT effectively addresses the issue of catastrophic forgetting that can occur during full fine-tuning of LLMs, as it updates only a limited set of parameters.
Enhanced Performance in Low-Data Scenarios: PEFT methods have demonstrated superior performance in situations with limited data, and they exhibit better generalization to out-of-domain scenarios compared to full fine-tuning.
Portability Advantage: PEFT approaches enable users to obtain compact checkpoints, typically a few megabytes in size, in contrast to the larger checkpoints produced by full fine-tuning. This makes it convenient to deploy and utilize the trained weights from PEFT for various tasks without the need to replace the entire model.
Comparable Performance to Full Fine-Tuning: PEFT allows achieving performance on par with full fine-tuning while utilizing only a small number of trainable parameters.
Conclusion
The challenges associated with fine-tuning large language models, such as high memory requirements and computational burden, have prompted researchers to create innovative solutions like LoRa, QLoRa and other parameter efficient fine-tuning methods. By creating a balance between computational power and performance, these techniques make the power of large language models more accessible and applicable to an array of tasks. As natural language processing continues to advance, the importance of such computation-friendly and efficient methods will undoubtedly continue to grow.
Resources
https://github.com/huggingface/peft [Repo]
Introduction to PEFT [Blogpost]
A Guide to PEFT [Blogpost]
A practical guide to PEFT [Blogpost]