TL;DR
This blogpost tries to explain Retrieval Augmented Generation. Retrieval Augmented Generation is an Architecture used for NLP tasks which can be used to productionize LLM models for enterprise architecture easily.
Why should i care?
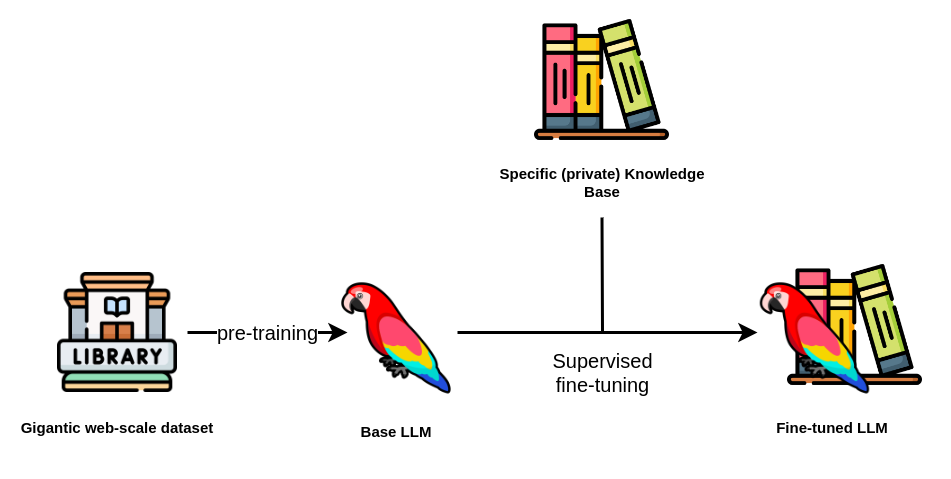
Intuitive would be to train a Large Language Model with domain specific data, in other words, to fine-tune the model-weights with custom data.
 picture from Neo4J
picture from Neo4J
But fine-tuning large language models (LLMs) is a complex and resource-intensive process due to several key factors:
- Acquiring the massive computational infrastructure required to train LLMs effectively demands significant financial investment. Even if you rely on Cloud Providers instead of on-premise the cost to train is a factor which cannot be neglected currently.
- Assembling high-quality, domain-specific datasets for fine-tuning can be time-consuming and expensive, as it often involves labor-intensive data collection and annotation efforts.
Other downsides are:
- Hallucinations: If you think about it consequently fine-tuning will not guarantee that the model behaves the way you would like it to behave. We are able to steer how the model is “learning” when fine-tuning but we cannot control the outcome. The probability that we receive hallucinations is way higher if we fine-tune in contrast to if we just directly provide additional context in the prompt which is matching to our question.
- Retraining and Knowledge Cut-offs: It would require constant compute-intensive retraining for even small changes. As you would not do that every day every LLM has a training end date, post which it is unaware of events or information.
- Context Window: Each Large Language Model (LLM) functions within a contextual window, which essentially defines the maximum volume of information it can simultaneously accommodate. When external data sources provides information surpassing this window’s capacity, it needs to be segmented into smaller portions that align with the model’s contextual limitations.
Use Retrieval Augmented Generation
Research on NLP was there before the hype around GPT’s and specifically on OpenAIs service ChatGPT(based on GPT3.5) started in 2022. In 2020 Lewis et al. from Meta AI published a paper on Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
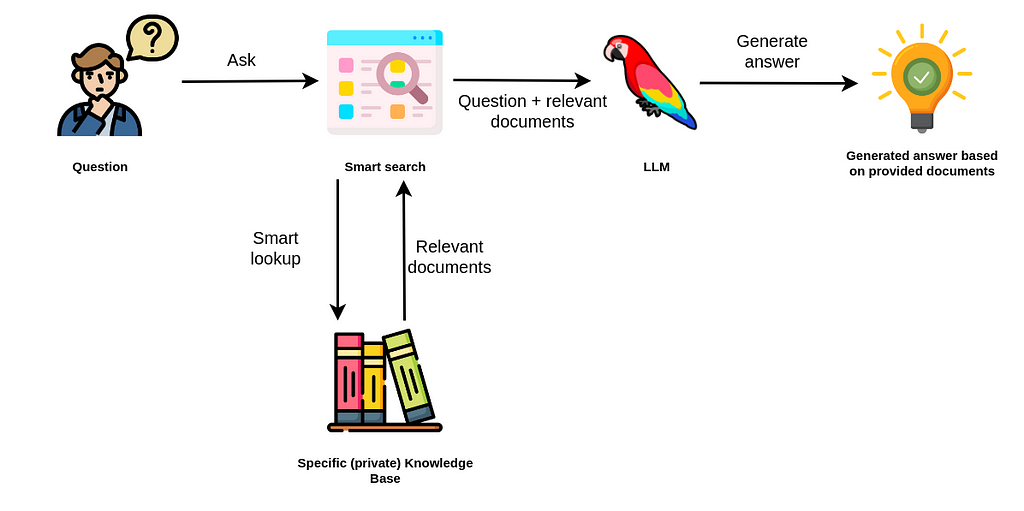
Retrieval-augmented generation (RAG) is an AI architecture for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLMs internal representation of information.
 picture from Neo4J
picture from Neo4J
“It’s the difference between an open-book and a closed-book exam,” Lastras said. “In a RAG system, you are asking the model to respond to a question by browsing through the content in a book, as opposed to trying to remember facts from memory.”
It is a fusion of two powerful NLP techniques: retrieval-based models and generative models. Retrieval-based models excel at finding relevant information from a vast pool of knowledge, often in the form of pre-existing text or documents. On the other hand, generative models are proficient in generating human-like text based on the given input.
Incorporating it into an LLM architecture enables the model to combine the best of both worlds.
- It can retrieve contextually relevant information from a vast knowledge base and
- use that information to generate coherent and contextually appropriate responses.
This approach leads to more accurate and context-aware interactions with the language model.
 picture from Lewis et al. (2021)
picture from Lewis et al. (2021)
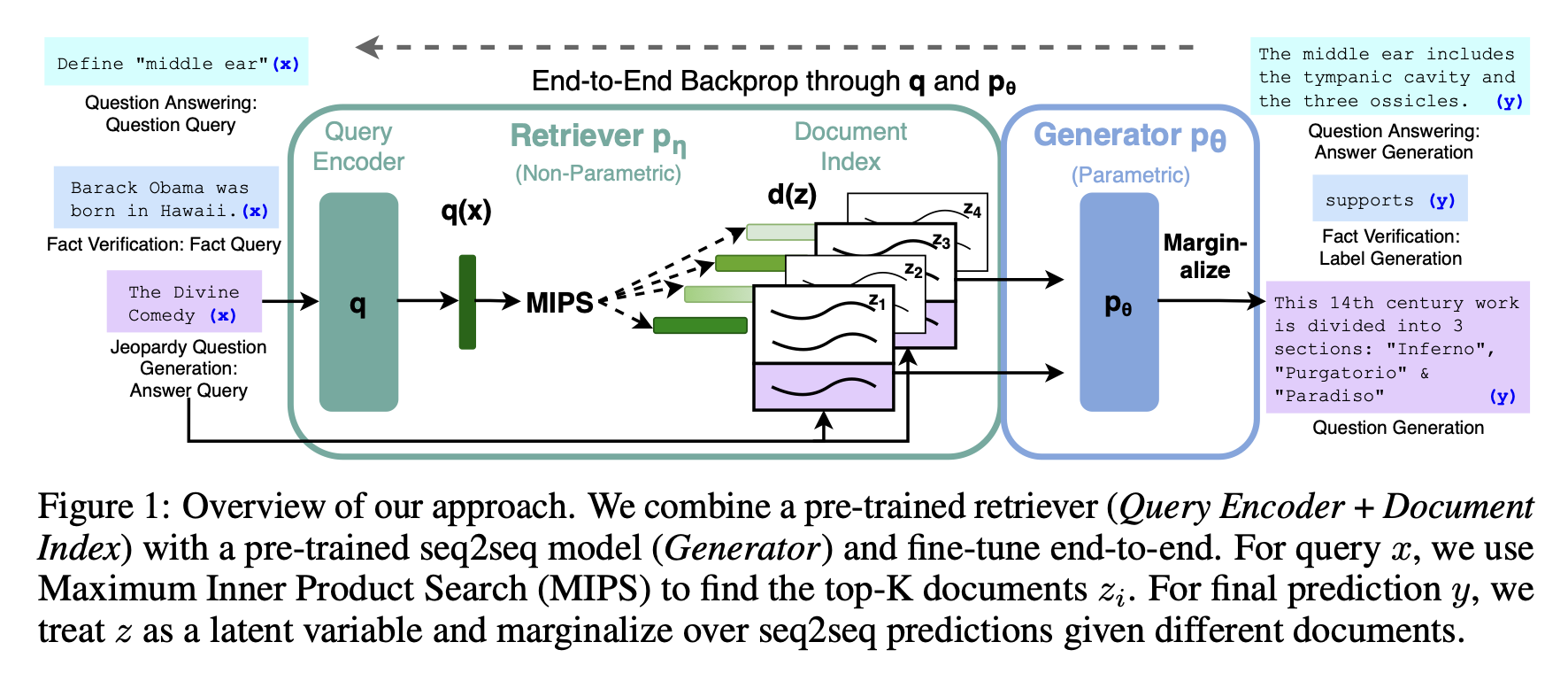
The architecture of an LLM incorporating retrieval augmented generation typically consists of two main components:
Retrieval Module
The retrieval module is the heart of the architecture and responsible for searching and retrieving relevant information from a large knowledge base. This knowledge base can be a collection of texts, documents, or even web pages. Retrieval can be broken down into two stages:
Indexing
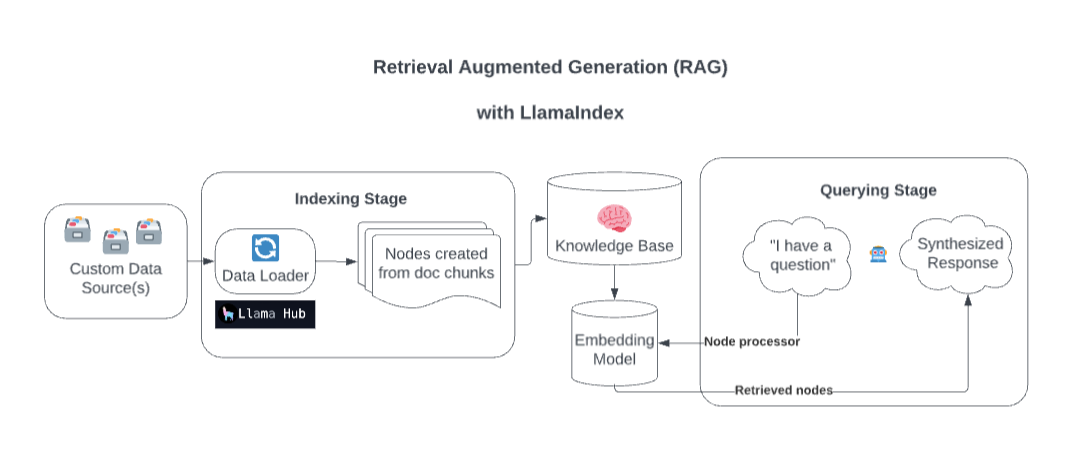
You will index the knowledge base which you want to give as context to the model. To index your data you can simply use libraries like LangChain llama_index or transformers which do the work for you. The data is loaded, chunked and tokenized. Data will be fetched from your various sources, segmented into bite-sized chunks to optimize them for embedding and search and afterwards tokenized to create embeddings. The embeddings are stored as high dimensional vectors in vector databases and build the foundation for RAG.
Let’s look into the implementation of RAG in llama_index, a famous orchestration network to further understand the indexing stage:
 picture and text from llama_index
picture and text from llama_index
Data Connectors: A data connector (i.e. Reader) ingest data from different data sources and data formats into a simple Document representation (text and simple metadata).
Documents / Nodes: A Document is a generic container around any data source - for instance, a PDF, an API output, or retrieved data from a database. A Node is the atomic unit of data in LlamaIndex and represents a “chunk” of a source Document. It’s a rich representation that includes metadata and relationships (to other nodes) to enable accurate and expressive retrieval operations.
Data Indexes: Once you’ve ingested your data, LlamaIndex will help you index the data into a format that’s easy to retrieve. Under the hood, LlamaIndex parses the raw documents into intermediate representations, calculates vector embeddings, and infers metadata. The most commonly used index is the VectorStoreIndex
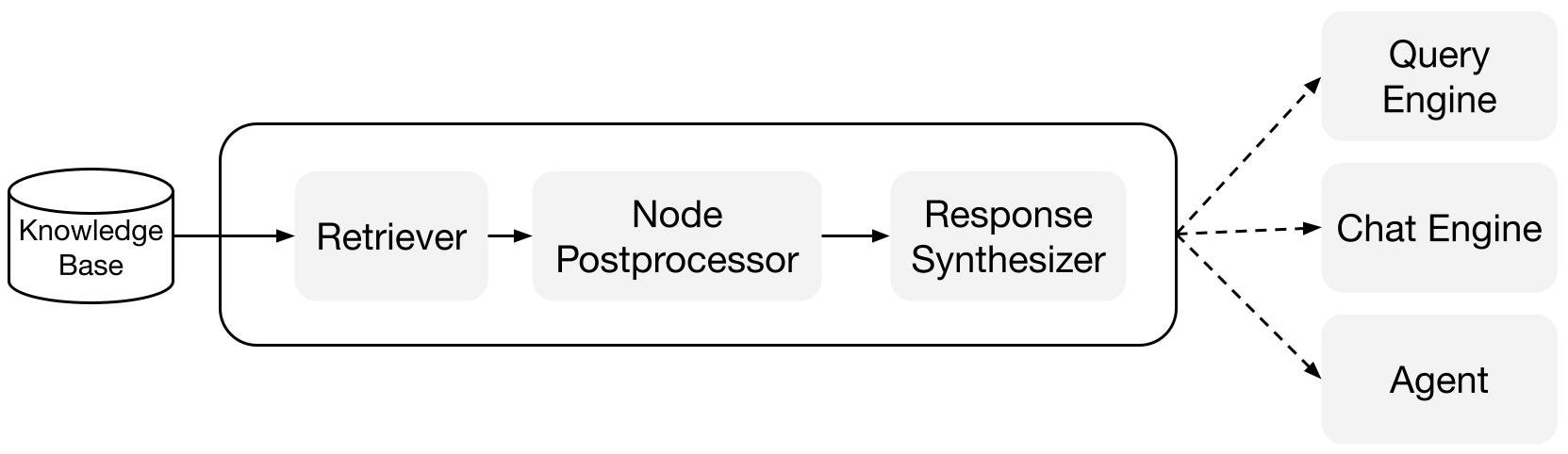
Querying
The data from the vector databases can be used for Semantic Search. Meaning that when a query is processed(into an embedding) the retriever can search for the most appropriate matching data in the vector database and give it to the generator as context. The retrieved data is combined with the original prompt, creating an enhanced or augmented prompt. This augmented prompt provides additional context. This is even more relevant for domain specific data which may not be part of the corpus used for training the model.
Again let’s look how this is implemented llama_index, to also understand the querying stage:
 picture and text from llama_index
picture and text from llama_index
Retrievers: A retriever defines how to efficiently retrieve relevant context from a knowledge base (i.e. index) when given a query. The specific retrieval logic differs for different indices, the most popular being dense retrieval against a vector index.
Node Postprocessors: A node postprocessor takes in a set of nodes, then apply transformation, filtering, or re-ranking logic to them.
Response Synthesizers: A response synthesizer generates a response from an LLM, using a user query and a given set of retrieved text chunks.
In summary: We start by searching for relevant documents or excerpts within an extensive dataset. For this a dense retrieval mechanism that leverages embeddings to represent both the query and the documents is used. These embeddings are then utilized to calculate similarity scores, leading to the retrieval of the top-ranked documents.
Generation Module
The generation module is based on a generative language model like GPT-3.5. It takes as input the retrieved information and the user’s query or context and generates a coherent response.
Example
An example architecture using llama_index would look like the following:
 picture from streamlit
picture from streamlit
The code for this example can be found on github. Also you can find a dedicated blogpost on my blog Hands on with Retrieval Augmented Generation.
Benefits of using RAG
Improved Precision: Through the utilization of external data sources, the RAG LLM can produce responses that are not solely derived from its training dataset but are also enriched by the most pertinent and current information accessible within the retrieval corpus.
Addressing Knowledge Gaps: RAG effectively confronts the inherent knowledge limitations of LLM, whether stemming from the model’s training cut-off or the absence of domain-specific data in its training corpus.
Adaptability: RAG can seamlessly integrate with an array of external data sources, encompassing proprietary databases within organizations and publicly accessible internet data. This adaptability makes it suitable for a broad spectrum of applications and industries.
Mitigating Hallucinations: A challenge associated with LLMs is the potential occurrence of “hallucinations,”. By incorporating real-time data context, RAG decreases the probability of such outputs.
Scalability: An advantage of RAG LLMs lies in its scalability. Through the separation of the retrieval and generation processes, the model can manage extensive datasets, making it well-suited for real-world scenarios characterized by abundant data.
Pitfalls
Of course there is a downside with retrieval systems. They rely on semantic search. Semantic Search has a simple assumption which leads to problems:
Question and answer have a high semantic similarity.
This assumption seems easy and straightforward but it is oversimplifying human language. Semantic Search only looks for explicit matches not for negation or implicit matches.
A simple example
Think of following example:
initial sentence:
“I like Bananas”
vs
“I don’t like Bananas”
“I like every fruit but bananas”
“I love this divine yellow fruit. It is curved like a smile and I feel like a monkey when I eat it.”
I think it is clear where i am pointing at. The sentences are already ordered from highest to lowest similarity.
Of course there is potential to overcome this with additional heuristics but for sure we need to understand that every architecture we built is implicitly build on assumptions that influence the outcome.
Conclusion
Retrieval augmented generation is a versatile hack.
In the early days of LLM adoption - where we are still at - it is a good technique to rapidly deliver production grade systems which are more efficient and less prone for hallucinations.
Due to the implicit assumptions and with it bias humans are bringing into the architecture in the future there will be better ways to deliver a good outcome. But for now it is highly relevant to consider Retrieval Augmented Generation for building LLM powered solutions.
Resources
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
IBM: What is retrieval-augmented generation?
Retrieval meets Long Context Large Language Models